All about Structure:
Adapting Structural Information across Domains for Boosting Semantic Segmentation
![]()
![]()
![]()
![]()
![]()
![]()









@inproceedings{chang2019all,
title={All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation},
author={Chang, Wei-Lun and Wang, Hui-Po and Peng, Wen-Hsiao and Chiu, Wei-Chen},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
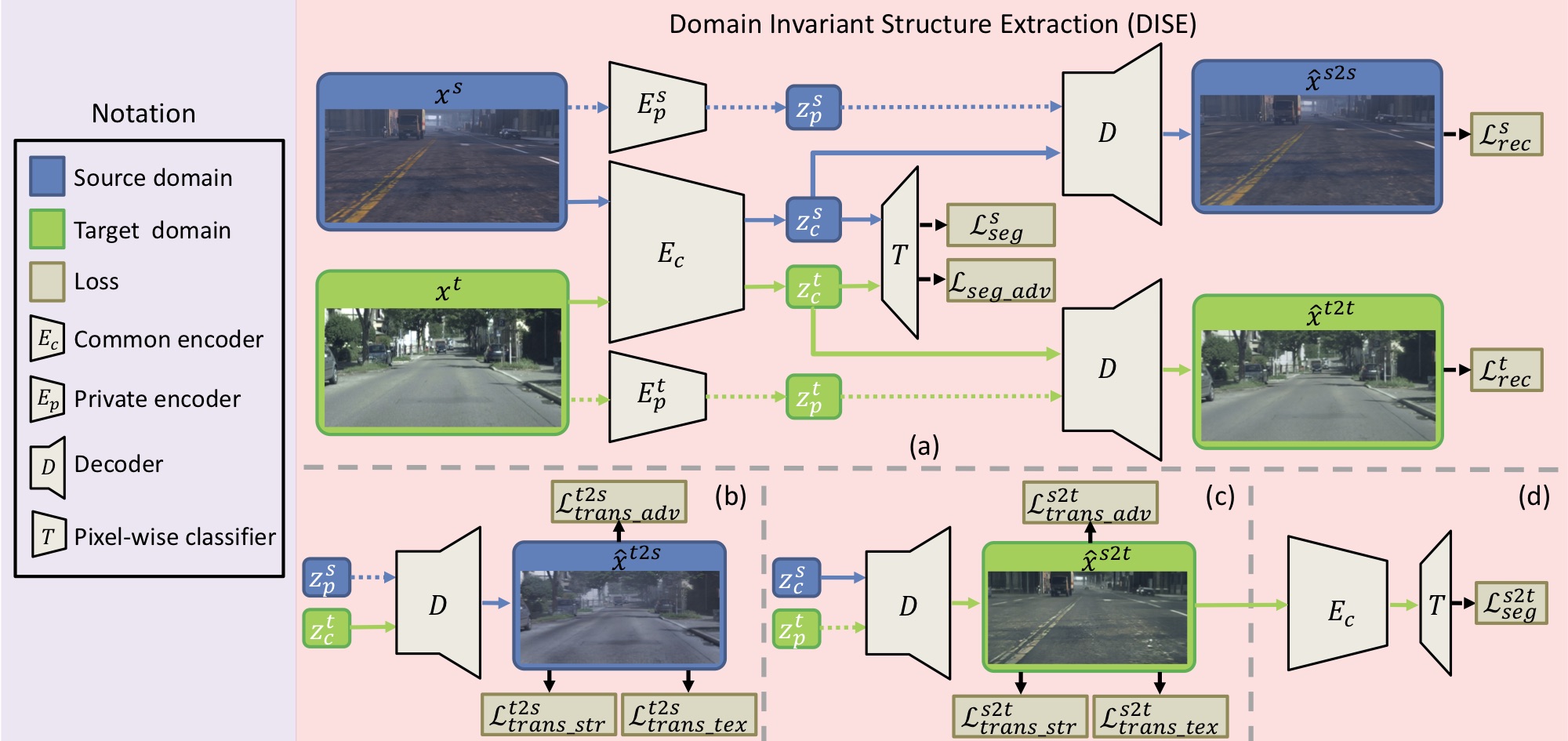
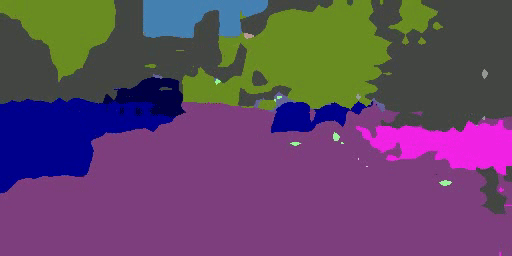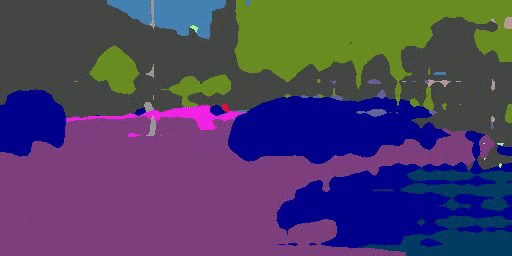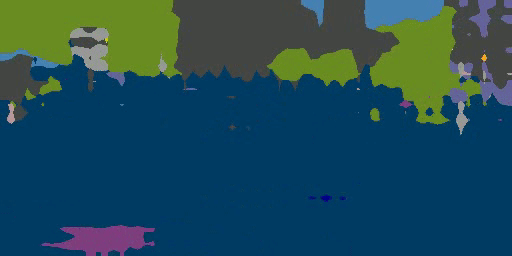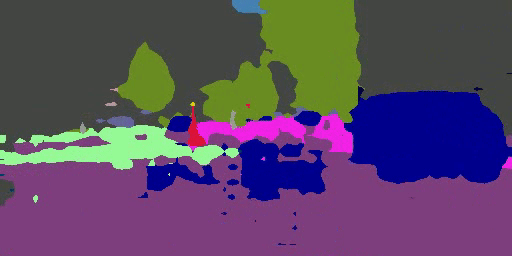
An overview of the proposed domain-invariant structure extraction (DISE) framework for semantic segmentation. The DISE framework is composed of a common encoder $E_c$ shared across domains, two domain-specific private encoders, $E_p^s, E_p^t$, a pixel-wise classifier $T$, and a shared decoder $D$. It encodes an image, source-domain or target-domain, into a domain-specific texture component $z_p$ and a domain-invariant structure component $z_c$, as shown in part (a). With this disentanglement, it can translate an image $x^s$ (respectively, $x^t$) in one domain to another image $\hat{x}^{s2t}$ (respectively, $\hat{x}^{t2s}$) in the other domain by combining the structure content of $x^s$ (respectively, $x^t$) with the texture appearance of $x^t$ (respectively, $x^s$), as shown in parts (b) and (c). This further enables the transfer of ground-truth labels from the source domain to the target domain, as illustrated in part (d).